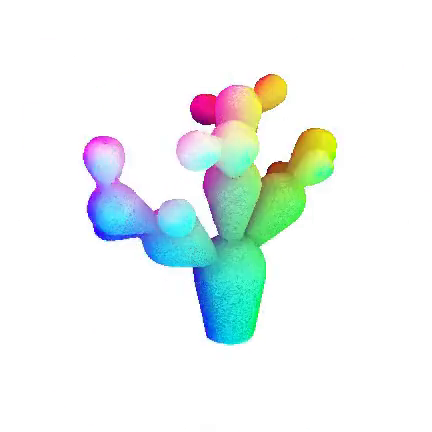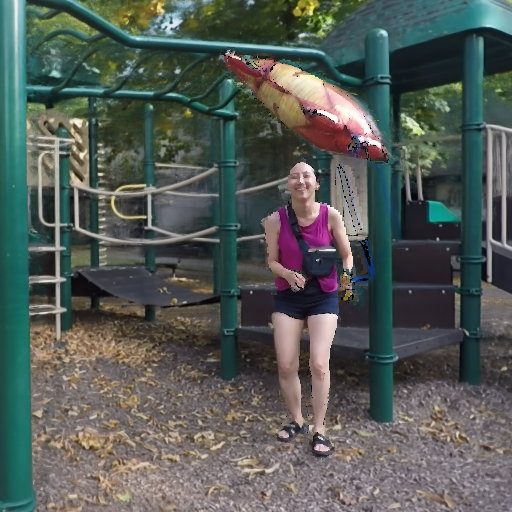I am passionate about multimodal intelligence, computer vision, and generative models, with the broader goal of unifying perception, generation, and reasoning in visual and multimodal systems.
During my graduate study, I interned at Apple, Meta Reality Labs, and Google, conducting research related to above topics.
We introduce a framework for learning latent representations of 4D objects which are descriptive, compressive, and accessible (requiring minimal input).
Velox: Learning Representations of 4D Geometry and Appearance
@inproceedings{Malik2026Velox,
author = {Anagh Malik and Dorian Chan and Xiaoming Zhao and David B. Lindell and Oncel Tuzel and Jen-Hao Rick Chang},
title = {{Velox: Learning Representations of 4D Geometry and Appearance}},
booktitle = {arXiv},
year = {2026},
}
We propose a 3D latent representation that jointly models object geometry and view-dependent appearance, enabling high-quality image-to-3D generation.
LiTo: Surface Light Field Tokenization
@inproceedings{chang2026lito,
author = {Jen-Hao Rick Chang$^\ast$ and Xiaoming Zhao$^\ast$ and Dorian Chan and Oncel Tuzel},
title = {{LiTo: Surface Light Field Tokenization}},
booktitle = {ICLR},
year = {2026},
}
We find both classifier guidance and classifier-free guidance achieve conditional generation by pushing the denoising diffusion trajectories away from data distribution's decision boundaries.
Studying Classifier(-Free) Guidance From a Classifier-Centric Perspective
@inproceedings{zhao2025OnCFG,
author = {Xiaoming Zhao and Alexander G. Schwing},
title = {{Studying Classifier(-Free) Guidance From a Classifier-Centric Perspective}},
booktitle ={AAAI},
year ={2026},
}
We show, for the first time, that latent 3D representations learned from modeling 3D surface probability densities can scale and perform competitively.
3D Shape Tokenization via Latent Flow Matching
@article{chang2025shapetoken,
author = {Jen-Hao Rick Chang and Yuyang Wang and Miguel Angel Bautista Martin and Jiatao Gu and Xiaoming Zhao and Josh Susskind and Oncel Tuzel},
title = {{3D Shape Tokenization via Latent Flow Matching}},
journal = {arXiv},
year = {2025},
}
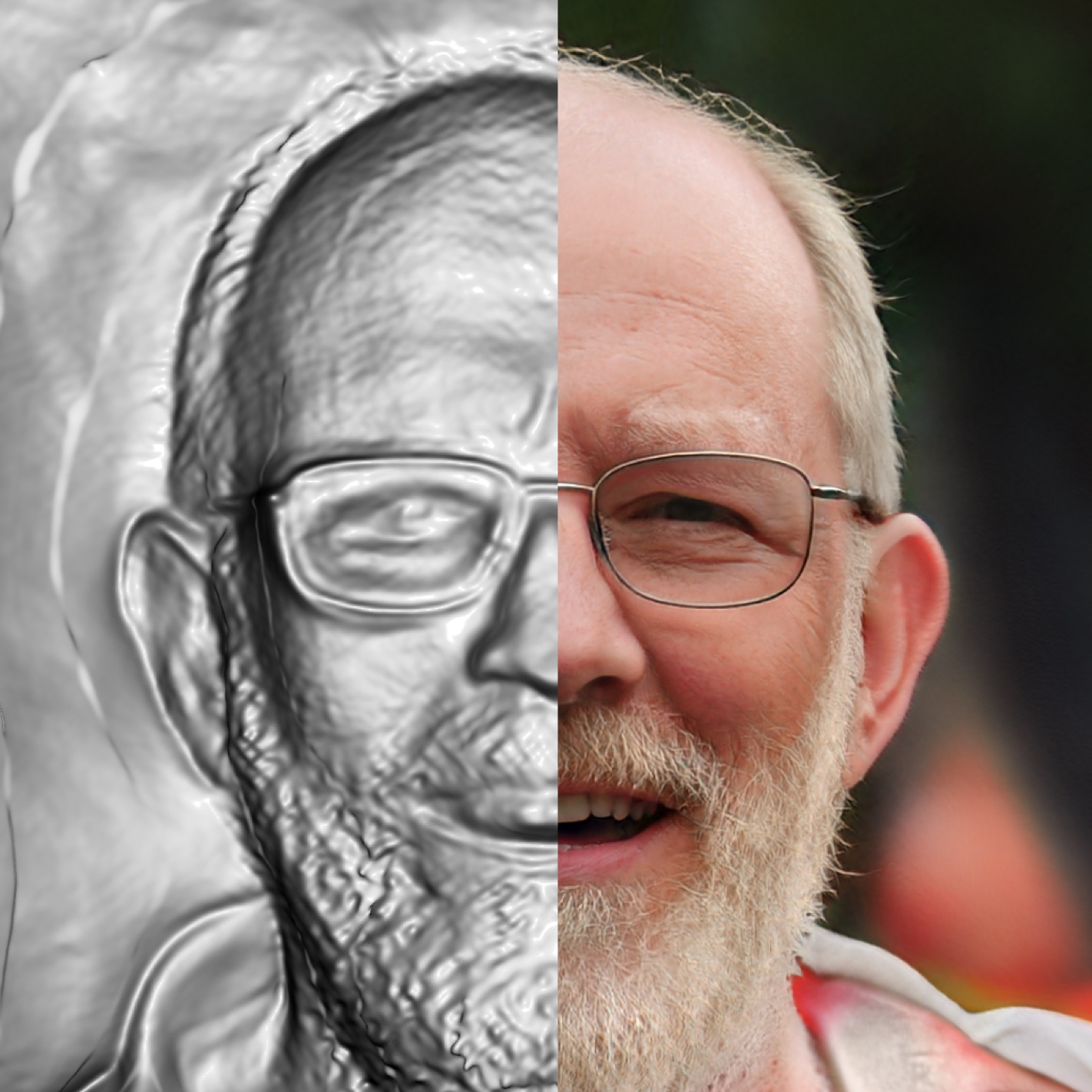
IllumiNeRF provides a simpler approach than traditional inverse rendering for 3D relighting: distilling samples from a single-image relighting diffusion model into a latent-variable NeRF.
IllumiNeRF: 3D Relighting Without Inverse Rendering
@inproceedings{zhao2024illuminerf,
author = {Xiaoming Zhao and Pratul P. Srinivasan and Dor Verbin and Keunhong Park and Ricardo Martin Brualla and Philipp Henzler},
title = {{IllumiNeRF: 3D Relighting Without Inverse Rendering}},
booktitle = {NeurIPS},
year = {2024},
}
GoMAvatar introduces Gaussians-on-Mesh (GoM) representation for real-time, memory-efficient, and high-quality animatable human modeling.
GoMAvatar: Efficient Animatable Human Modeling From Monocular Video Using Gaussians-on-Mesh
@inproceedings{wen2024GoM,
title={{GoMAvatar: Efficient Animatable Human Modeling From Monocular Video Using Gaussians-on-Mesh}},
author={Jing Wen and Xiaoming Zhao and Zhongzheng Ren and Alex Schwing and Shenlong Wang},
booktitle={CVPR},
year={2024},
}
NeRFDeformer automatically modifies a NeRF representation based on a single RGB-D observation of a non-rigid transformed version of the original scene.
NeRFDeformer: NeRF Transformation From a Single View via 3D Scene Flows
@inproceedings{tang2024nerfdeformer,
title={{NeRFDeformer: NeRF Transformation From a Single View via 3D Scene Flows}},
author={Zhenggang Tang and Zhongzheng Ren and Xiaoming Zhao and Bowen Wen and Jonathan Tremblay and Stan Birchfield and Alex Schwing},
booktitle={CVPR},
year={2024},
}
PGDVS provides an analysis framework for generalized dynamic view synthesis and finds with consistent depth estimations, scene-specific appearance optimization is NOT required.
Pseudo-Generalized Dynamic View Synthesis From a Video
@inproceedings{Zhao2024PGDVS,
title={{Pseudo-Generalized Dynamic View Synthesis From a Video}},
author={Xiaoming Zhao and Alex Colburn and Fangchang Ma and Miguel Angel Bautista and Joshua M. Susskind and Alexander G. Schwing},
booktitle={ICLR},
year={2024},
}
OPlanes provides more flexibility than voxel grids and enables to better leverage correlations than per-point classification.
Occupancy Planes for Single-View RGB-D Human Reconstruction
@inproceedings{Zhao2023Oplanes,
title={{Occupancy Planes for Single-View RGB-D Human Reconstruction}},
author={Xiaoming Zhao and Yuan-Ting Hu and Zhongzheng Ren and Alexander G. Schwing},
booktitle={AAAI},
year={2023},
}
GMPI guarantees to be view-consistent and enables fast training (in less than half a day at a resolution of 10242) and high FPS during inference.
Generative Multiplane Images: Making a 2D GAN 3D-Aware
@inproceedings{zhao2022gmpi,
title = {{Generative Multiplane Images: Making a 2D GAN 3D-Aware}},
author = {Xiaoming Zhao and Fangchang Ma and David Güera and Zhile Ren and Alexander G. Schwing and Alex Colburn},
booktitle = {ECCV},
year = {2022},
}
Carefully designed initialization and alignment procedures enable benefiting from both classical and recent learning-based texture optimization techniques.
Initialization and Alignment for Adversarial Texture Optimization
@inproceedings{zhao2022tex,
title = {{Initialization and Alignment for Adversarial Texture Optimization}},
author = {Xiaoming Zhao and Zhizhen Zhao and Alexander G. Schwing},
booktitle = {ECCV},
year = {2022},
}
REDO enables class-agnostic geometry reconstruction for dynamic objects from RGB-D videos.
Class-agnostic 4D Reconstruction From Videos
@inproceedings{ren2021redo,
title = {{Class-agnostic Reconstruction of Dynamic Objects From Videos}},
author = {Zhongzheng Ren$^\ast$ and Xiaoming Zhao$^\ast$ and Alexander G. Schwing},
booktitle = {NeurIPS},
year = {2021},
note = {$^\ast$ equal contribution},
}
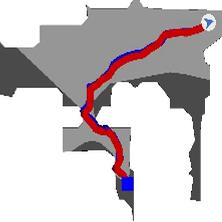
A well-trained visual odometry module can be a drop-in replacement for GPS and Compass sensor in PointGoal navigation.
The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation
@inproceedings{Zhao2021pointnav,
title={{The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation}},
author={Xiaoming Zhao and Harsh Agrawal and Dhruv Batra and Alexander G. Schwing},
booktitle={ICCV},
year={2021},
}
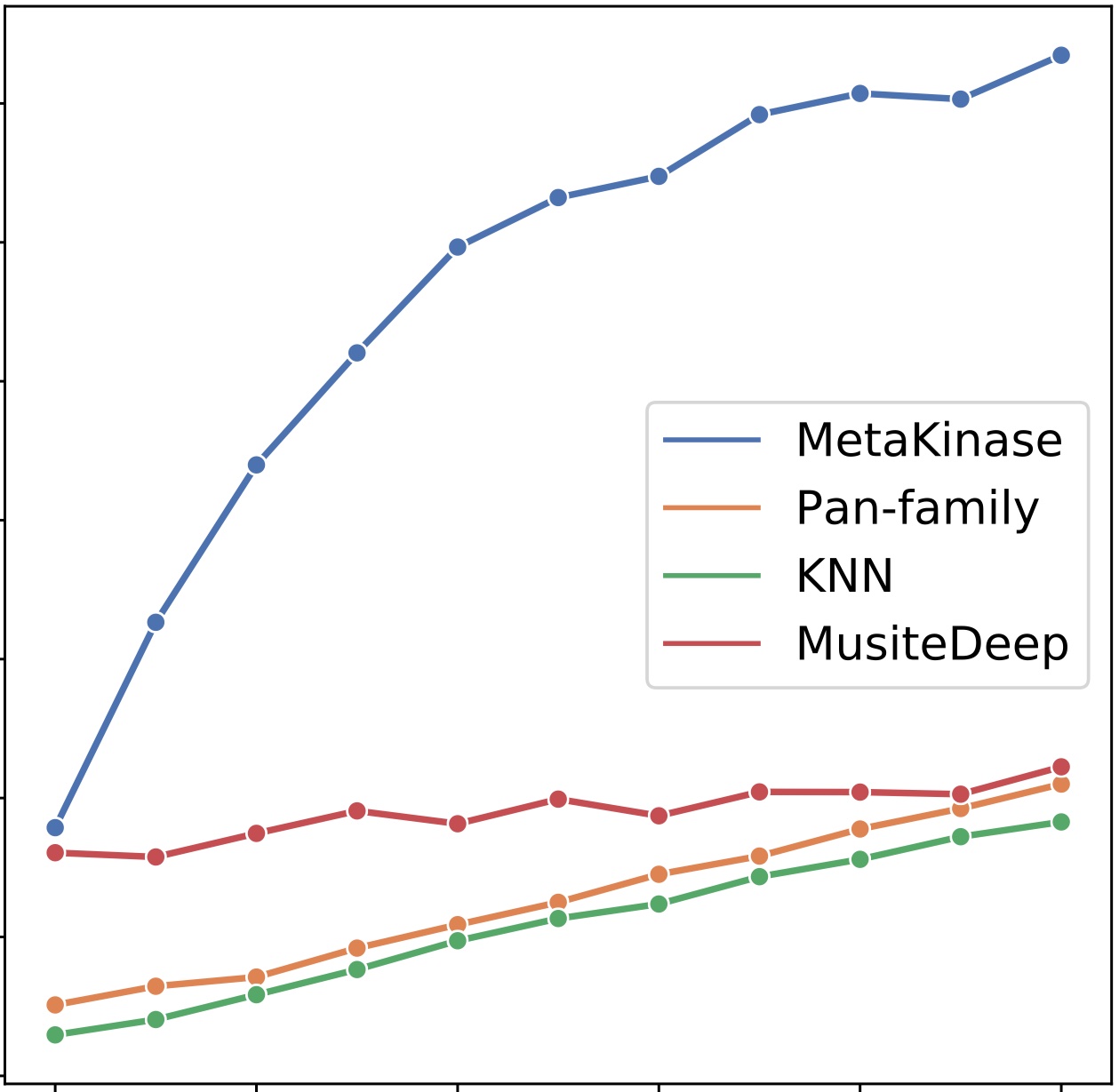
Meta-learning and few-shot learning strategy can be utilized to mitigate the data scarcity issue in characterizing the specificity of less-studied kinases for protein-peptide binding prediction.
Mitigating Data Scarcity in Protein Binding Prediction Using Meta-Learning
@inproceedings{luo2019mitigating,
title={{Mitigating Data Scarcity in Protein Binding Prediction Using Meta-Learning}},
author={Luo, Yunan and Ma, Jianzhu and Zhao, Xiaoming and Su, Yufeng and Liu, Yang and Ideker, Trey and Peng, Jian},
booktitle={RECOMB},
year={2019},
}
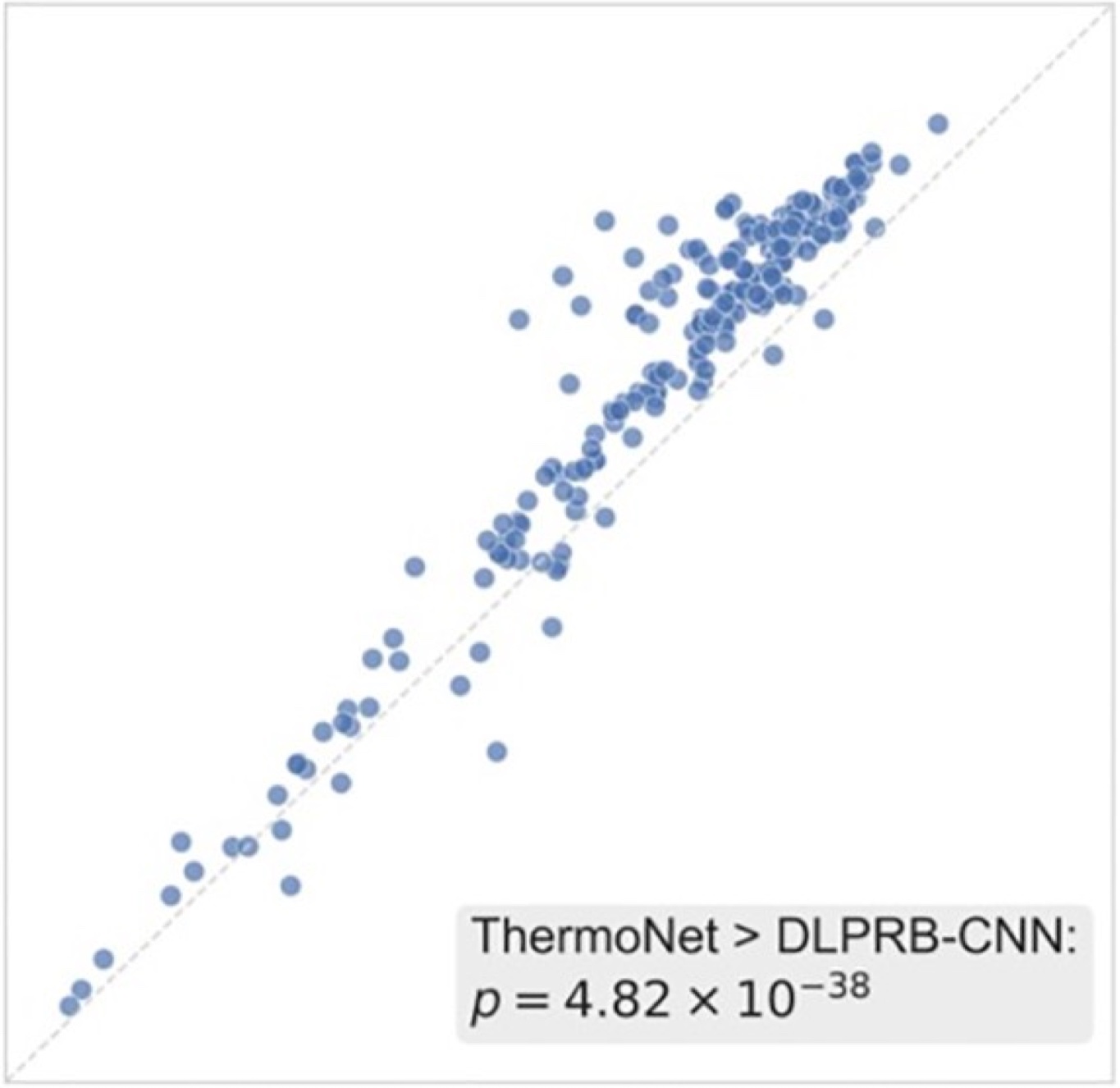
A deep learning-based thermodynamic model is introduced for protein-RNA binding prediction.
Integrating Thermodynamic and Sequence Contexts Improves Protein-RNA Binding Prediction
@article{su2019integrating,
title={{Integrating Thermodynamic and Sequence Contexts Improves Protein-RNA Binding Prediction}},
author={Su, Yufeng and Luo, Yunan and Zhao, Xiaoming and Liu, Yang and Peng, Jian},
journal={PLOS Computational Biology},
year={2019},
}
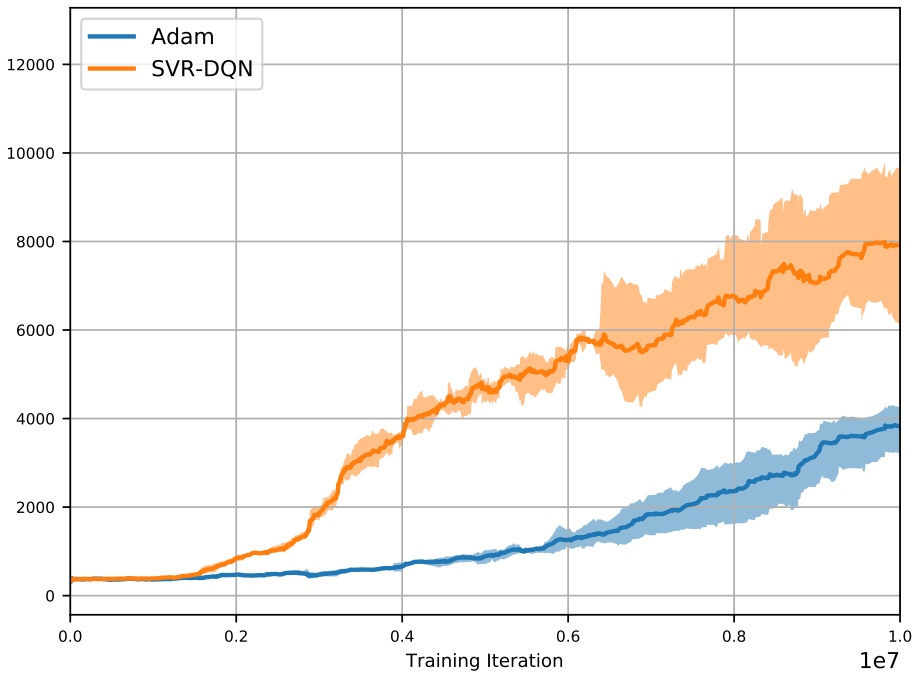
@article{Zhao2019RLarxiv,
title={{Stochastic Variance Reduction for Deep Q-Learning}},
author={Wei-Ye Zhao and Xi-Ya Guan and Yang Liu and Xiaoming Zhao and Jian Peng},
journal={arXiv},
year={2019},
}